Explore, visualize, modele. Uma melhor percepção começa com Stata
Rápido. Preciso. Fácil de usar. Stata é um pacote de software completo e integrado que fornece todas as suas necessidades de ciência de dados — manipulação de dados, visualização, estatísticas e relatórios automatizados.
Gerenciamento de dados
Estatísticas
Gráficos
Por que Stata?
Rápido. Preciso. Fácil de usar. Stata é um pacote de software completo e integrado que fornece todas as suas necessidades de ciência de dados — manipulação de dados, visualização, estatísticas e relatórios automatizados.
|
|
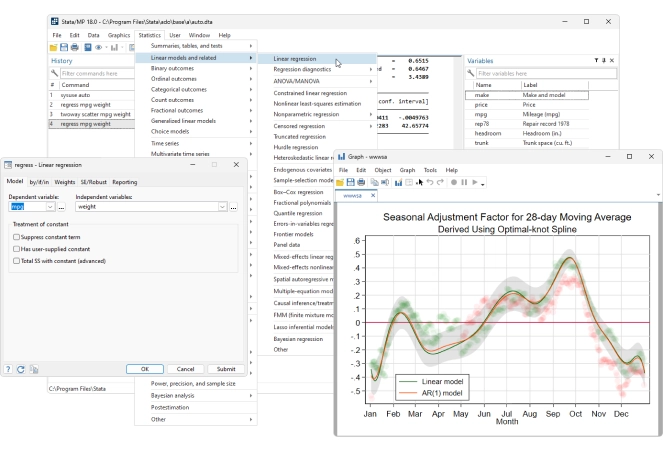
Domine seus dados
Os recursos de gerenciamento de dados do Stata oferecem controle total.
|
|
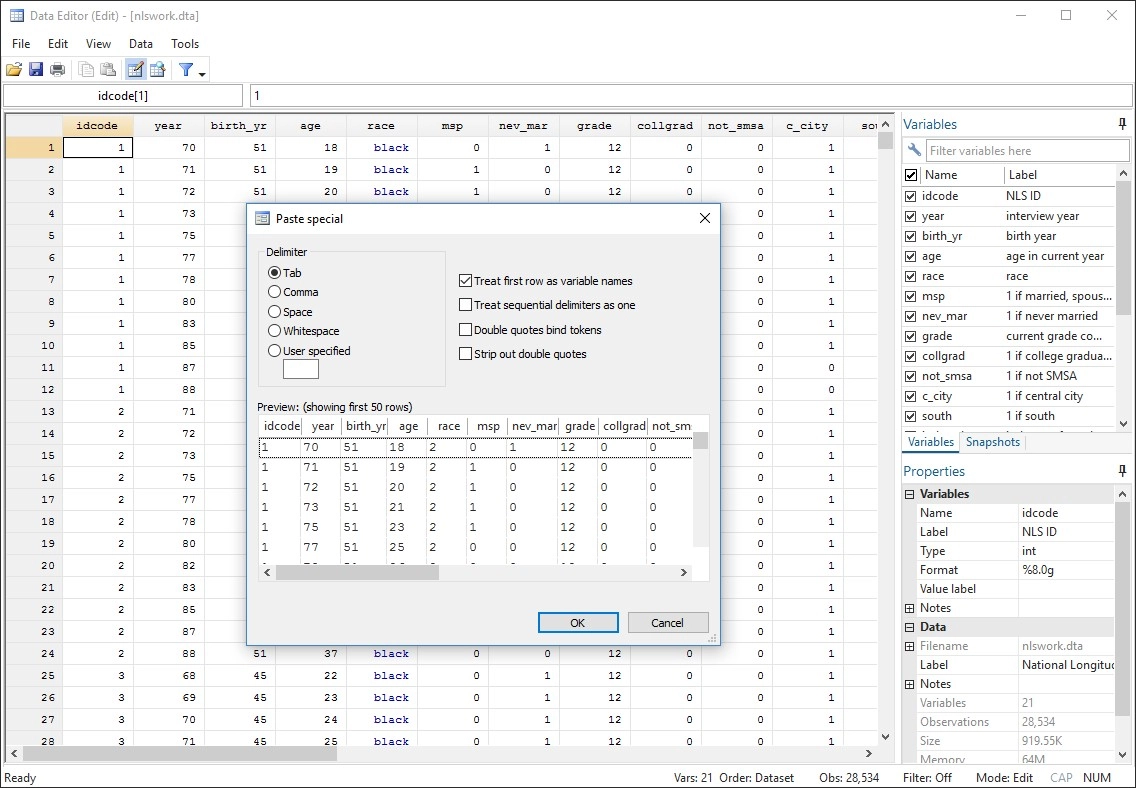
Gráficos de qualidade de publicação
O Stata facilita a geração de gráficos com estilo distinto e qualidade de publicação.
Você pode apontar e clicar para criar um gráfico personalizado. Ou você pode escrever scripts para produzir centenas ou milhares de gráficos de forma reproduzível.
Exporte gráficos para EPS ou TIFF para publicação, para PNG ou SVG para a web ou para PDF para visualização.
Com o Editor de Gráficos integrado, você clica para alterar qualquer coisa no seu gráfico ou para adicionar títulos, notas, linhas, setas e texto.
Relatórios automatizados
Todas as ferramentas que você precisa para automatizar a geração de relatórios de resultados.
- Documento Markdown dinâmico
- Criar documentos do Word
- Criar documentos PDF
- Criar arquivos Excel
- Tabelas personalizáveis
- Esquemas para gráficos
- Palavra, HTML, PDF, SVG, PNG
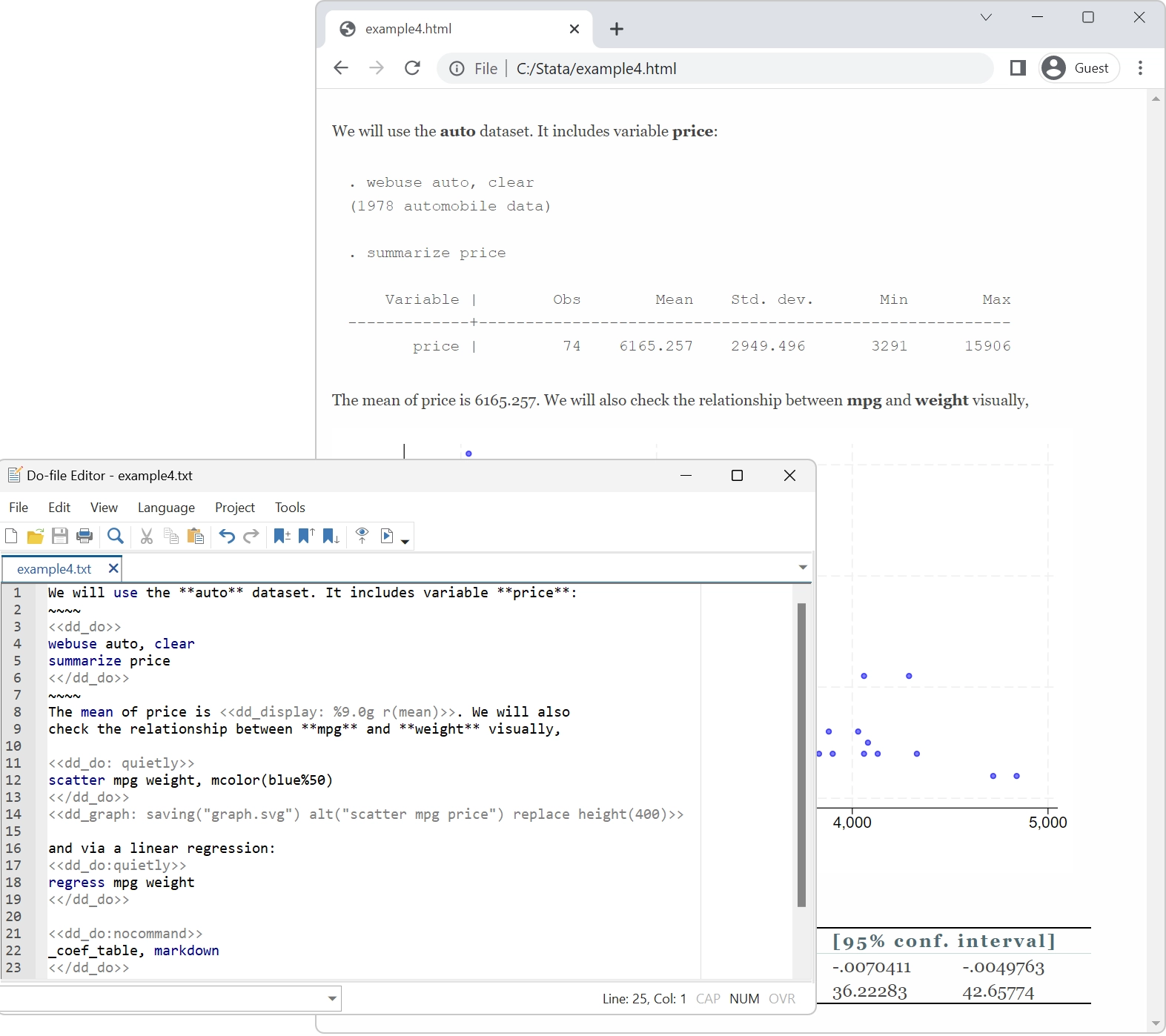
Pesquisa verdadeiramente reproduzível
Muitas pessoas falam sobre pesquisa reprodutível. A Stata se dedica a isso há mais de 30 anos.
Adicionamos constantemente novos recursos; até mesmo mudamos fundamentalmente elementos de linguagem. Não importa. O Stata é o único pacote estatístico com controle de versão integrado. Se você escreveu um script para executar uma análise em 1985, esse mesmo script ainda será executado e produzirá os mesmos resultados hoje. Qualquer conjunto de dados que você criou em 1985, você pode ler hoje. E o mesmo será verdade em 2050. O Stata será capaz de executar qualquer coisa que você faça hoje.
Levamos a reprodutibilidade a sério.
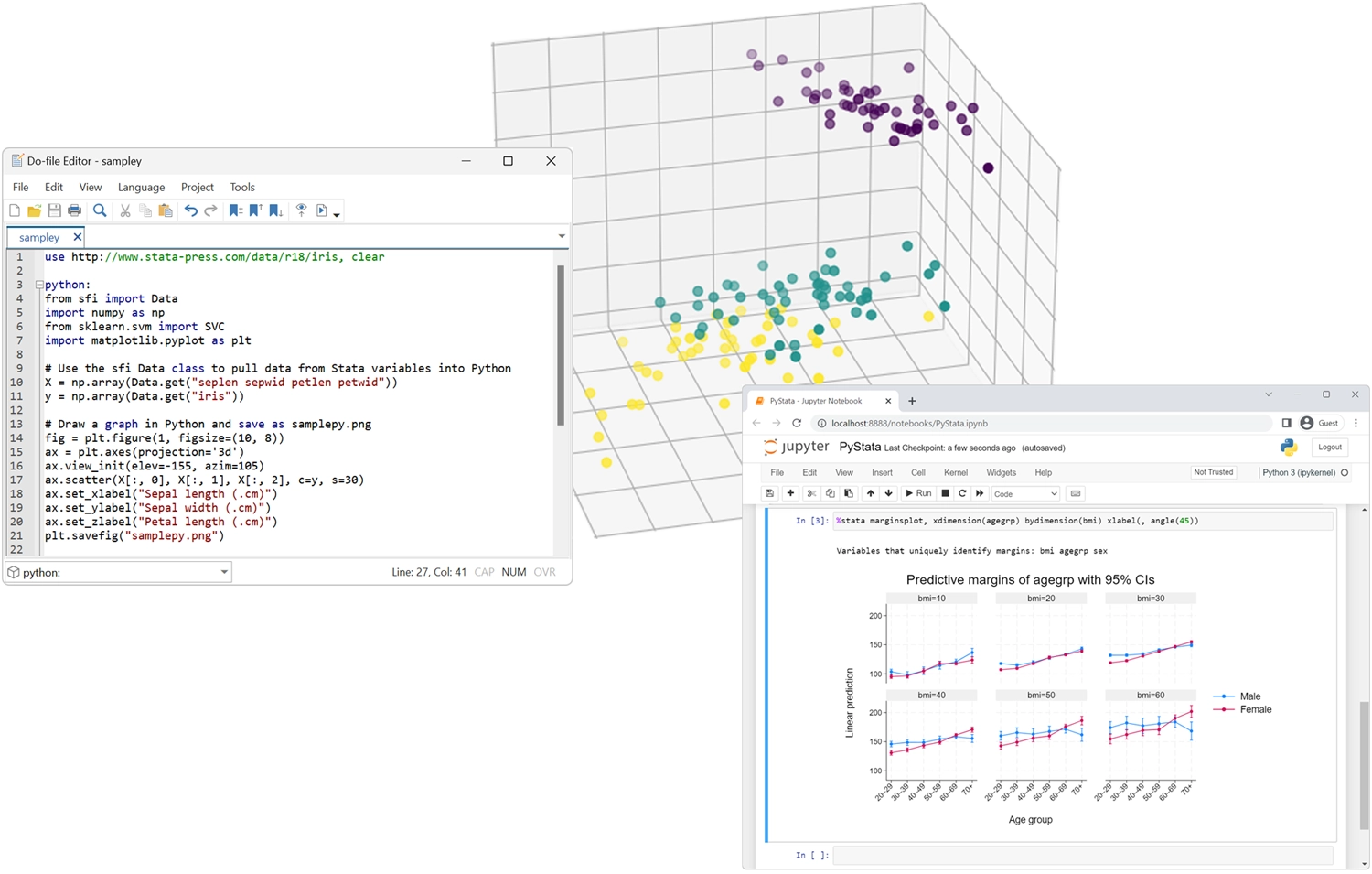
PyStata - Integração Python
Invoque o Python interativamente ou incorpore o Python no seu código Stata.
Invoque o Stata do Python e chame o código Stata dos ambientes IPython.
Use o Stata no Jupyter Notebook.
Passe dados e resultados facilmente entre Stata e Python.
Use análises Stata dentro do Python.
Use qualquer pacote Python dentro do Stata
- Matplotlib e seaborn para visualização
- Beautiful Soup e Scrapy para web scraping
- NumPy e pandas para análise numérica
- TensorFlow e scikit-learn para aprendizado de máquina
- E muito mais
Documentação Real
Quando chega a hora de realizar suas análises ou entender os métodos que você está usando, o Stata não deixa você na mão nem pedindo livros para aprender cada detalhe.
Cada um dos nossos recursos de gerenciamento de dados é totalmente explicado e documentado e mostrado na prática em exemplos reais. Cada estimador é totalmente documentado e inclui vários exemplos em dados reais, com discussões reais sobre como interpretar os resultados. Os exemplos fornecem os dados para que você possa trabalhar no Stata e até mesmo estender as análises. Oferecemos um Início rápido para cada recurso, mostrando alguns dos usos mais comuns. Quer ainda mais detalhes? Nossas seções de Métodos e fórmulas fornecem as especificações do que está sendo computado, e nossas Referências apontam para ainda mais informações.
O Stata é um pacote grande e, portanto, tem muita documentação – mais de 18.000 páginas em 35 manuais. Mas não se preocupe, digite help my topic, e o Stata pesquisará suas palavras-chave, índices e até mesmo pacotes contribuídos pela comunidade para trazer tudo o que você precisa saber sobre seu tópico. Tudo está disponível dentro do Stata.
Confiável
Nós não apenas programamos métodos estatísticos, nós os validamos.
Os resultados que você vê de um estimador Stata se baseiam em comparações com outros estimadores, simulações de Monte Carlo de consistência e cobertura e testes extensivos por nossos estatísticos. Cada Stata que enviamos passou por um conjunto de certificação que inclui 4,1 milhões de linhas de código de teste que produz 5,8 milhões de linhas de saída. Nós certificamos cada número e pedaço de texto dessas 5,8 milhões de linhas de saída.
Confiável
Por mais de 35 anos, a StataCorp tem sido leal aos seus usuários ao expandir o software Stata com novos métodos estatísticos e o que há de mais moderno em relatórios, visualização de dados, manipulação de dados e interface do usuário. Com nosso histórico de lançamentos de longa data, estamos comprometidos em fornecer continuamente software estável e confiável para nossa comunidade diversificada de pesquisadores e profissionais.
![]()
Atualizado continuamente
Manter a versão mais atualizada do Stata agora é mais fácil do que nunca.
A StataCorp desenvolve continuamente novos recursos para aprimorar o software Stata, desde os métodos estatísticos mais recentes até o melhor em relatórios, visualização de dados e interface do usuário. Com o StataNow™, novos recursos são lançados durante o lançamento atual até o próximo lançamento principal. Esses recursos são priorizados no ciclo de desenvolvimento para estarem disponíveis assim que estiverem prontos, para que os usuários possam aproveitá-los imediatamente.
![]()
Fácil de usar
Manter a versão mais atualizada do Stata agora é mais fácil do que nunca.
Todos os recursos do Stata podem ser acessados por meio de menus, diálogos, painéis de controle, um Data Editor, um Variables Manager, um Graph Editor e até mesmo um SEM Diagram Builder. Você pode apontar e clicar em qualquer análise.
Se você não quiser escrever comandos e scripts, não precisa.
Mesmo quando você estiver apontando e clicando, você pode registrar todos os seus resultados e depois incluí-los em relatórios. Você pode até salvar os comandos criados por suas ações e reproduzir sua análise completa mais tarde.
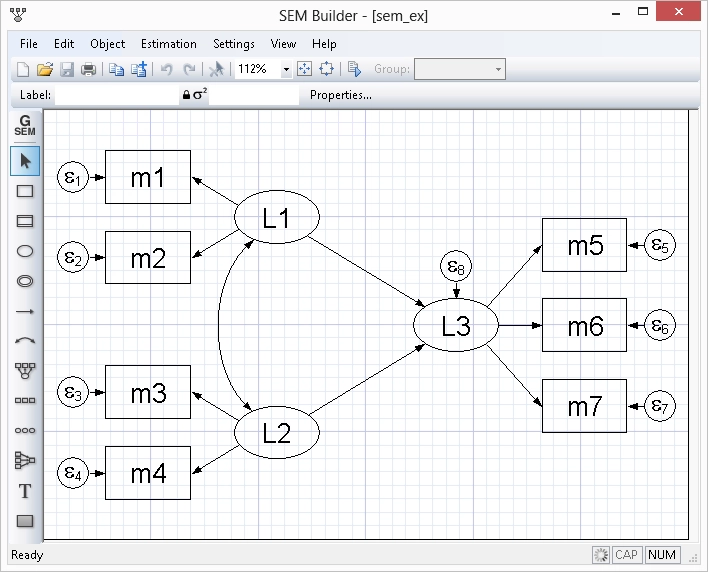
Fácil de cultivar com
Os comandos do Stata para executar tarefas são intuitivos e fáceis de aprender. Melhor ainda, tudo o que você aprende sobre executar uma tarefa pode ser aplicado a outras tarefas. Por exemplo, você simplesmente adiciona if gender=="female" a qualquer comando para limitar sua análise a mulheres em sua amostra. Você simplesmente adiciona vce(robust) a qualquer estimador para obter erros padrão e testes de hipóteses que são robustos a muitas suposições comuns.
A consistência vai ainda mais fundo. O que você aprende sobre comandos de gerenciamento de dados geralmente se aplica a comandos de estimativa e vice-versa. Há também um conjunto completo de comandos de pós-estimação para executar testes de hipóteses, formar combinações lineares e não lineares, fazer previsões, formar contrastes e até mesmo executar análises marginais com gráficos de interação. Esses comandos funcionam da mesma forma após praticamente todos os estimadores.
Sequenciar comandos para ler e limpar dados, depois executar testes estatísticos e estimativas e, finalmente, relatar resultados é o cerne da pesquisa reproduzível. O Stata torna esse processo acessível a todos os pesquisadores.
![]()
Fácil de automatizar
Todo mundo tem tarefas que faz o tempo todo — criar um tipo específico de variável, produzir uma tabela específica, executar uma sequência de etapas estatísticas, calcular um RMSE, etc. As possibilidades são infinitas. O Stata tem milhares de procedimentos integrados, mas você pode ter tarefas que são relativamente únicas ou que você quer que sejam feitas de uma maneira específica.
Se você escreveu um script para executar sua tarefa em um determinado conjunto de dados, é fácil transformar esse script em algo que pode ser usado em todos os seus conjuntos de dados, em qualquer conjunto de variáveis e em qualquer conjunto de observações.
![]()
Fácil de estender
Algumas das coisas que você automatiza podem ser tão úteis que você deseja compartilhá-las com colegas ou até mesmo disponibilizá-las para todos os usuários do Stata. Isso também é fácil. Com apenas um pouco de código, você pode transformar um script de automação em um comando Stata. Um comando que suporta recursos padrão que os comandos oficiais do Stata suportam. Um comando que pode ser usado da mesma forma que os comandos oficiais são usados.
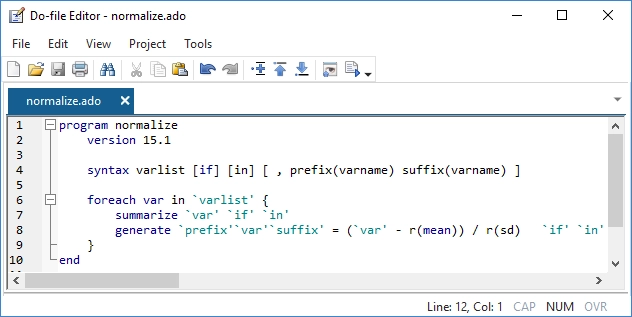
Programação Avançada
O Stata também inclui uma linguagem de programação avançada: Mata.
Mata tem as estruturas, ponteiros e classes que você espera em sua linguagem de programação e adiciona suporte direto para programação matricial.
Embora você não precise programar para usar o Stata, é reconfortante saber que uma linguagem de programação rápida e completa é parte integrante do Stata. O Mata é um ambiente interativo para manipulação de matrizes e um ambiente de desenvolvimento completo que pode produzir código compilado e otimizado. Ele inclui recursos especiais para processamento de dados de painel, executa operações em matrizes reais ou complexas, fornece suporte completo para programação orientada a objetos e é totalmente integrado a todos os aspectos do Stata. O Stata também tem integração abrangente com o Python, permitindo que você aproveite todo o poder do Python diretamente do seu código Stata.
O Stata também tem o PyStata, que fornece integração abrangente com o Python, permitindo que você aproveite todo o poder do Python diretamente do seu código Stata e aproveite todo o poder do Stata do seu código Python.
O Stata ainda permite que você incorpore plugins C, C++ e Java em seus programas Stata por meio de uma API nativa para cada linguagem. E você pode até mesmo incorporar código Java diretamente em seu código Stata!

Recursos contribuídos pela comunidade
O Stata é tão programável que desenvolvedores e usuários adicionam novos recursos todos os dias para responder às crescentes demandas dos pesquisadores de hoje.
Com os recursos de Internet do Stata, novos recursos e atualizações oficiais podem ser instalados pela Internet com um único clique.
Suporte técnico de classe mundial
Todos os usuários registrados da versão atual do Stata (Stata 18) são elegíveis para suporte técnico gratuito. Se você não registrou sua cópia do Stata, preencha o formulário de registro online.
Temos uma equipe dedicada de programadores e estatísticos especialistas em Stata para responder às suas perguntas técnicas. De soluções complicadas de gerenciamento de dados a deixar seu gráfico com a aparência correta e de explicar um erro padrão robusto a especificar seu modelo multinível, temos suas respostas.
![]()
Compatível com várias plataformas
O Stata rodará em computadores Windows, Mac e Linux/Unix; no entanto, nossas licenças não são específicas para cada plataforma. Isso significa que se você tem um laptop Mac e um desktop Windows, não precisa de duas licenças separadas para rodar o Stata. Você pode instalar sua licença Stata em qualquer uma das plataformas suportadas. Os conjuntos de dados, programas e outros dados do Stata podem ser compartilhados entre plataformas sem tradução. Você também pode importar conjuntos de dados de outros pacotes estatísticos, planilhas e bancos de dados de forma rápida e fácil.
Amplamente utilizado
Usado por pesquisadores há mais de 35 anos, o Stata fornece tudo o que você precisa para ciência de dados: manipulação de dados, visualização, estatísticas e relatórios automatizados.
Selecione sua disciplina e veja como o Stata pode funcionar para você.
O que há de novo no Stata 19
Leve sua pesquisa mais longe com os recursos mais recentes do Stata 19.
O Stata 19 tem algo para todos. Abaixo listamos os destaques deste lançamento. O Stata 19 é único porque a maioria dos novos recursos pode ser usada por pesquisadores em todas as disciplinas.
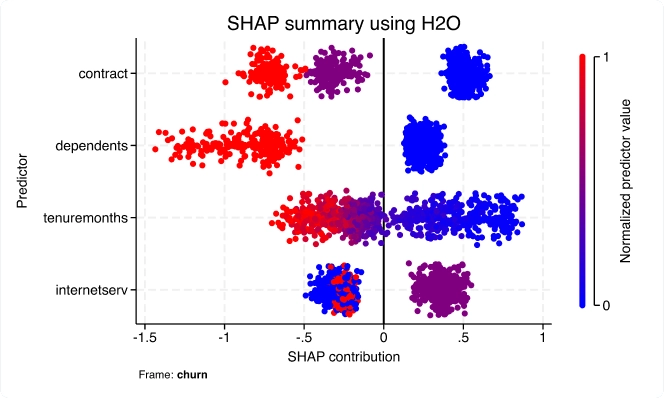
Aprendizado de máquina via H2O: Árvores de decisão de conjunto
Com o novo conjunto h2oml, use machine learning via H2O para descobrir insights de dados quando modelos estatísticos tradicionais falham. Métodos de machine learning são frequentemente usados para resolver problemas de pesquisa e negócios focados em predição.
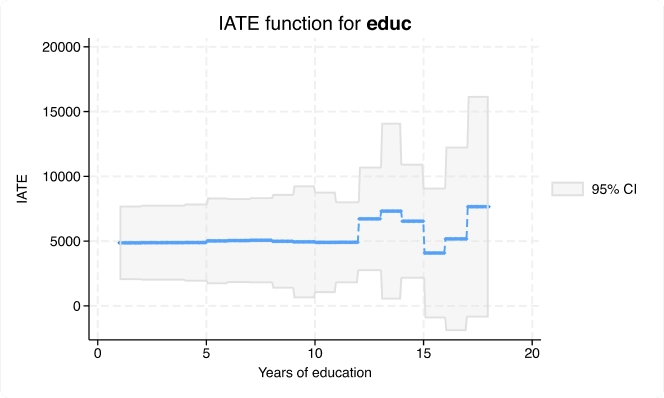
Efeitos médios condicionais do tratamento (CATE)
Com o novo comando cate, você pode ir além da estimativa de um efeito geral do tratamento e estimar efeitos individualizados ou específicos do grupo que abordam esses tipos de questões de pesquisa.

Efeitos fixos de alta dimensão (HDFE)
Absorva não apenas uma, mas várias variáveis categóricas de alta dimensão em seus modelos lineares e lineares de efeitos fixos com a opção absorb() dos comandos areg e xtreg.
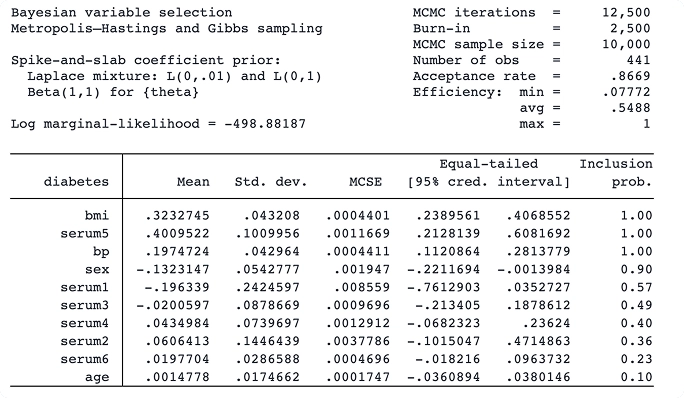
Seleção de variáveis bayesianas para regressão linear
Com o novo comando bayesselect, você pode executar seleção de variáveis bayesianas para regressão linear. Essa abordagem oferece interpretação intuitiva e inferência estável, considerando a incerteza do modelo.
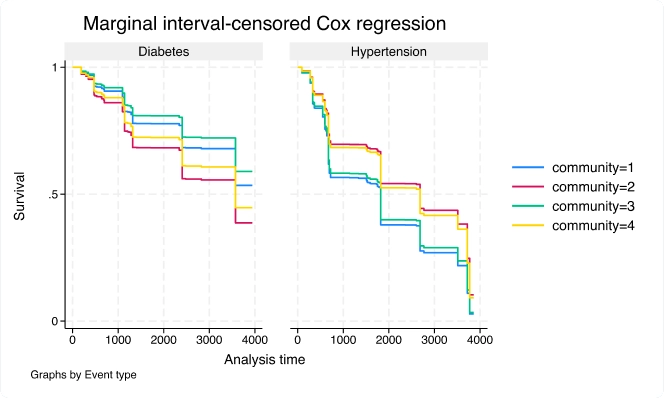
Modelos marginais de Cox PH para dados de eventos múltiplos censurados por intervalo
Use o novo comando stmgintcox para analisar dados de eventos múltiplos censurados por intervalo.
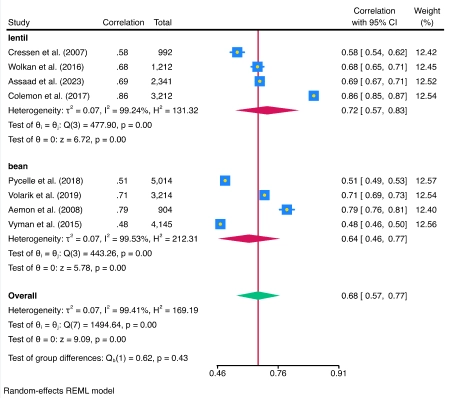
Meta-análise para correlações
O meta suite agora suporta meta-análise (MA) de um coeficiente de correlação. Todos os recursos de meta-análise padrão, como gráficos de floresta e análise de subgrupo, são suportados.

Modelo de efeitos aleatórios correlacionados (CRE)
Quer estimativas de coeficientes de covariáveis invariantes no tempo em seu modelo de dados em painel? Com xtreg, cre , agora você pode ajustar um modelo de efeitos aleatórios correlacionados.
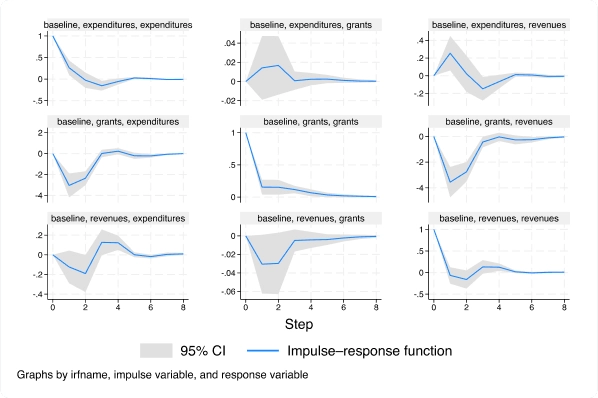
Modelo vetorial autorregressivo (VAR) de dados em painel
Com o novo comando xtvar, agora você pode ajustar um modelo autorregressivo (VAR) de vetor de dados em painel para analisar as trajetórias de variáveis relacionadas ao observar várias unidades ou painéis ao longo do tempo.
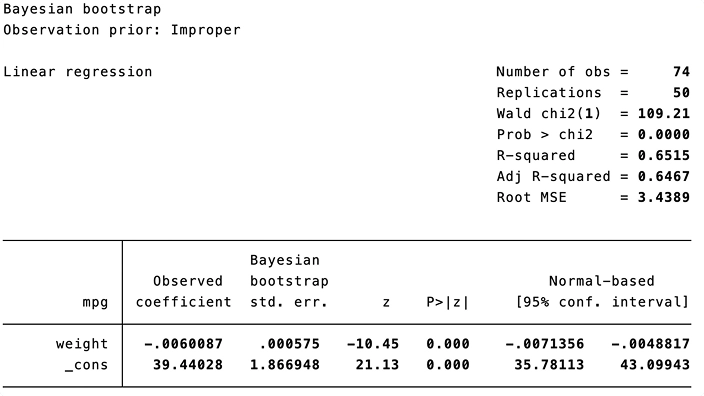
Pesos de bootstrap e replicação bayesianos
Você pode usar o novo prefixo bayesboot para executar bootstrap bayesiano de estatísticas produzidas por comandos oficiais e contribuídos pela comunidade. O bootstrap bayesiano pode incorporar informações anteriores para obter estimativas de parâmetros mais precisas.
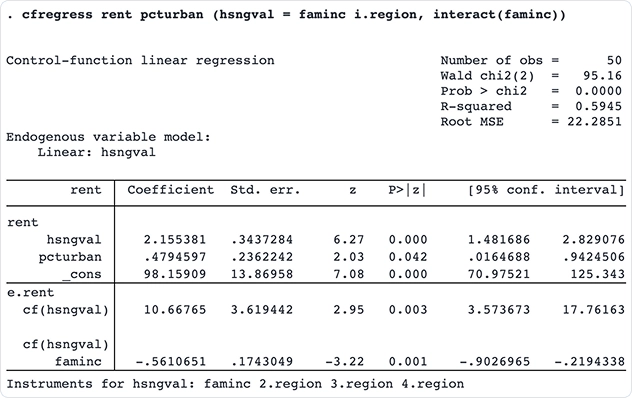
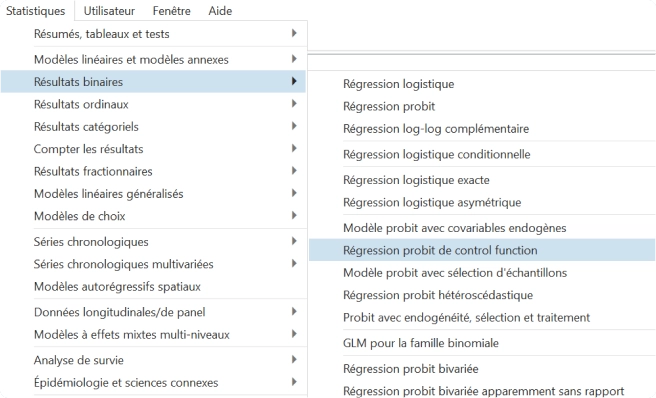
Modelos lineares e probit de função de controle
Ajuste modelos lineares e probit de função de controle com os novos comandos cfregress e cfprobit. Os modelos de função de controle oferecem uma abordagem mais flexível aos métodos tradicionais de variáveis instrumentais (IV) ao incluir variáveis endógenas.
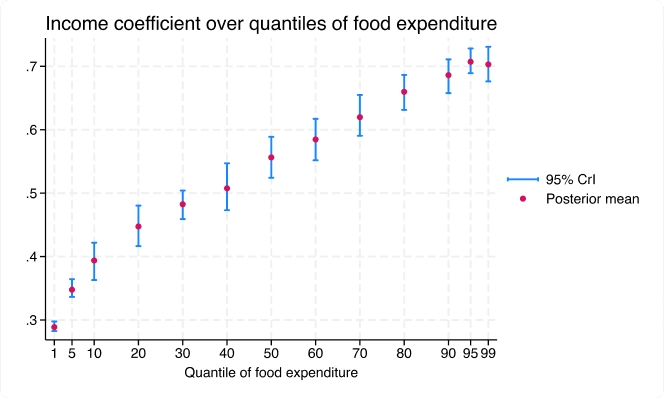
Regressão quantílica bayesiana via verossimilhança de Laplace assimétrica
O novo comando bayes: qreg se ajusta à regressão quantílica bayesiana. A estrutura bayesiana fornece distribuições posteriores completas para coeficientes de regressão quantílica que oferecem inferência abrangente.

Inferência robusta para instrumentos fracos
Use o novo comando estat weakrobust para realizar inferência confiável em regressores endógenos.
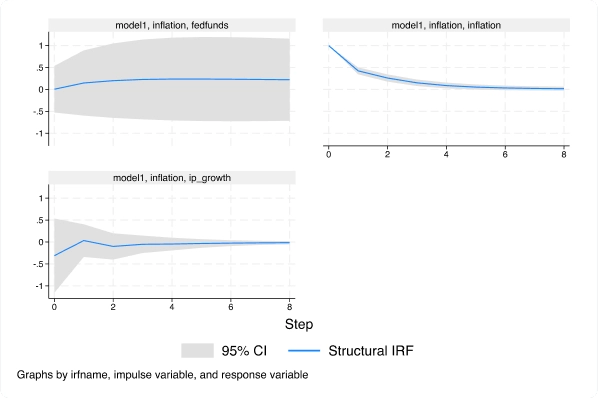
Modelos estruturais vetoriais autorregressivos (SVAR) via variáveis instrumentais
Com o novo comando ivsvar, você pode usar instrumentos em vez de restrições de curto prazo para estimar efeitos causais dinâmicos.
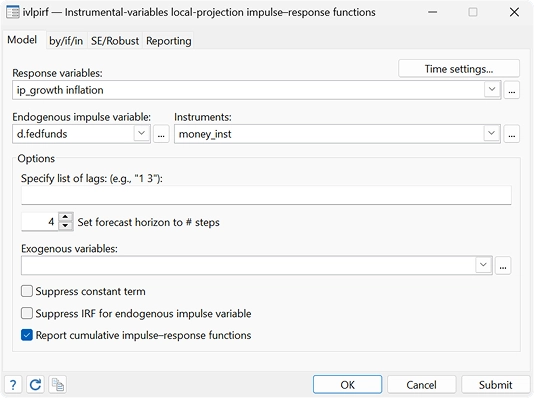
Variáveis instrumentais IRFs de projeção local
Com o novo comando ivlpirf, você pode levar em conta a endogeneidade ao usar projeções locais para estimar efeitos causais dinâmicos.

Teste de especificação Mundlak
Use o novo comando estat mundlak postestimation após xtreg para escolher entre modelos de efeitos aleatórios (RE), efeitos fixos (FE) ou efeitos aleatórios correlacionados (CRE), mesmo com erros padrão robustos de cluster, bootstrap ou jackknife.

Estatísticas de comparação de modelos de classes latentes
Com o novo comando lcstats, você pode usar estatísticas como entropia e uma variedade de critérios de informação para ajudar a determinar o número apropriado de classes.
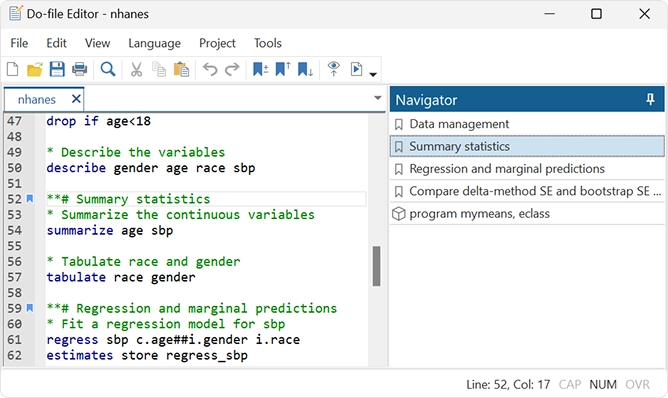
Editor de arquivo DO: preenchimento automático, modelos e muito mais
O Editor de arquivo Do tem as seguintes adições: Preenchimento automático de nomes de variáveis, macros e resultados armazenados; Melhorias na dobragem de código; Marcadores temporários e permanentes; Modelos, guias e painel de navegação.
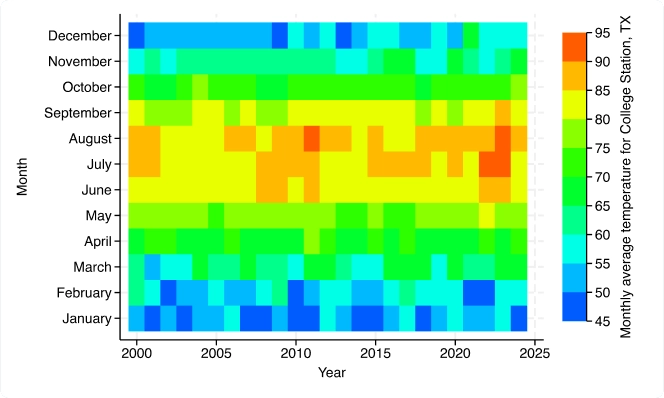
Gráficos: CIs de gráfico de barras, mapas de calor e muito mais
Novos recursos gráficos: Mapas de calor (bidirecional); Gráfico de alcance e ponto com picos limitados (bidirecional); Gráfico de alcance e ponto com picos (bidirecional); Rotulagem, ICs e controle de agrupamentos aprimorados para gráficos de barras, gráficos de pontos e diagramas de caixa; Cores por variável para mais gráficos.
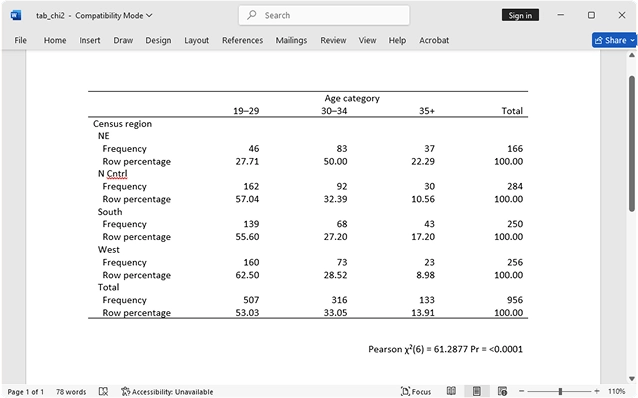
Tabelas: tabulações mais fáceis, exportação e muito mais
Crie e personalize tabelas facilmente com títulos, notas e exportação para tabelas. O comando table é uma ferramenta flexível para criar tabulações, tabelas de estatísticas de resumo, tabelas de resultados de regressão e muito mais.
Stata em francês
Os menus, diálogos e similares do Stata agora podem ser exibidos em francês. Se o idioma do seu computador estiver definido como francês (fr), o Stata usará automaticamente sua configuração em francês.
Apresentando StataNow™
Novos recursos lançados na velocidade do Stata. Com o StataNow, você sempre terá os recursos mais recentes.
O StataNow é uma versão de lançamento contínuo do Stata, que oferece novos recursos assim que ficam prontos e garante que os usuários sempre tenham acesso à versão mais recente do Stata.
Direto do desenvolvimento para você. Com StataNow, você sempre tem acesso aos recursos mais recentes.
Stata em sua pesquisa
Usado por centenas de milhares de pesquisadores por mais de 35 anos, o Stata fornece tudo o que você precisa para ciência de dados: manipulação de dados, visualização, estatísticas e relatórios reproduzíveis.
Selecione sua disciplina e veja como o Stata pode funcionar para você.
Usado por centenas de milhares de pesquisadores por mais de 35 anos, o Stata fornece tudo o que você precisa para ciência de dados: manipulação de dados, visualização, estatísticas e relatórios reproduzíveis.
Selecione sua disciplina e veja como o Stata pode funcionar para você.






