
Opening the Black Box: Machine Learning Methods
Individuals, consumers and businesses across a broad range of sectors frequently face the consequences of decisions based on evidence collected from data. Prominent examples include decisions on the availability of credit, whether or not a surgical intervention should be undertaken, the price of insurance premiums, and parole hearings.
The resulting quantification of human life through digital information, often for economic value, has produced datasets that include many thousands of records, but are wide in the sense of representing more information about each record.

Diebold (2003) refers to Big Data as “the explosion in the quantity (and sometimes, quality) of available and potentially relevant data, largely the result of recent and unprecedented advancements in data recording and storage technology.” In this note we use the term big data to refer to datasets where the width of data - namely the number of variables (or features) is large relative to the depth or specifically the number of observations.
Complementary to these developments has been significant advances in high dimensional statistics and machine learning (ML) methods more generally. As Lawrence (2019) notes, machine learning seeks to “emulate cognitive processes through the use of data.” Machine learning algorithms mimic this process using mathematical functions, differentiated by the type and number of parameters which control its behaviour. In this context “Learning” is the process of taking a set of inputs, and using a function to make it representative of the outcomes.
ML methods have been employed across a wide range of sectors. One prominent example is the detection of complex genomic interactions that can lead to diseases like diabetes, cancer, or Alzheimer’s. Here the challenge of big and “wide” data is especially pronounced given that although small individual differences in the gene sequence may have little effect, complex interactions among genes and environmental factors can result in significant effects. As McKinney et al (2021) note,

In the presence of high dimensional data, traditional statistical methods are not best suited to uncover these types of Interactions.
The Challenges of Big Data
Sparsity of data occurs when the volume of the data space represented grows so quickly that the data cannot keep up.
Figure 1 demonstrates this phenomenon. In moving from a)-c), the data space moves from one to three dimensions, with the given data filling less and less of the data space. In order to maintain an accurate representation of the space, the data for analysis needs to grow exponentially (3).
Figure 1: Sparsity and the Curse of Dimensionality
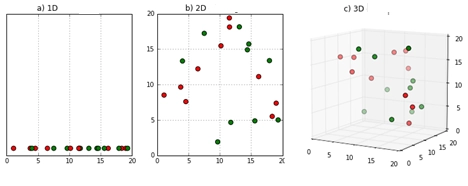
A model built upon sparse data will learn from the frequently occurring combinations of the attributes and will predict training outcomes accordingly. However, when the model is confronted by less frequently occurring combinations a problem of overfitting can result in a fall in prediction accuracy.
Unlocking the Value in Data
Economics and policymakers have also witnessed an exponential growth in both the depth and type of datasets. In this context data might constitute a high-dimensional array of numeric data or data in the form of text. In competition proceedings (4), questions such as whether merging parties are close competitors, or the extent to which customers of the merging parties supporting the proposed merger, cannot be addressed using standard quantitative data in tabular form. In this context Natural Language Processing is able to extract standardised qualitative data from textual information.
Speaking at the 2017 launch of Ofwat’s report - unlocking the value in customer data - Cathryn Ross, the then Chief Executive of Ofwat, emphasised that for companies to make the most of their data “they must understand the potential of the data they hold, as well as the role of econometrics and artificial-intelligence techniques such as machine learning (ML) in extracting more value from data.”
As an example a regulator would like to know the extent to which demographic variables, such as income, household size, and socio-economic status, are informative of the impact of energy policies on households. This is a difficult problem given that undertaking post hoc analysis as the set of demographic variables increase, runs into the well known multiplicity problem. In simple terms a key problem with this approach is that in mining the data for significant effects, the more one searches over a large set of possible effects, the more likely something will be found, with consequences for overfitting.
In assessing whether demographic variables are informative in terms of the impact of Time-of-Use tariffs on load profiles, the Customer-Led Network Revolution project noted ... a surprisingly consistent average demand profile across the different demographic groups, with much higher variability within groups than between them. This high variability is seen both in total consumption and in peak demand.
One reason for this finding might be that it is the (unknown) combination of low income (how low), household size (how big) and education (how little) that describes vulnerable customers. Or in other words, ex-ante segmentation based on a coarse set of demographics might not be informative.
In addition, unlocking value in data is not confined to simply determining which demographic variables are important.
Such an approach ignores the fact that many of these variables should be considered together, in a multiplicative fashion. However, finding such interacting sets of variables is challenging for many statistical models due to the “combinatorial space they need to interrogate, relative to the depth of the dataset”(5). This problem represents an accentuated form of the curse of dimensionality where the data available for building the model may not capture all possible combinations of the available information; in this sense the data space becomes sparse.
Machine Learning Methods
Machine learning methods developed in statistics and computer science have proven particularly powerful for predictive tasks. For example, hedonic pricing models, including models of house and car prices, seek to understand the impact of a large number of attributes on prices. In the interests of parsimony and addressing related problems of collinearity, and controlling the bias-variance trade-off, analysts have deployed methods from high-dimensional statistics (i.e ridge regression and Least Absolute Shrinkage and Selection (LASSO) ) and machine learning (i.e. random forests and generalised random forests) to identify the most important variables.

In this context the critical observation is that the impact of a policy also depends on how effective it is in selecting its targets. Examples include hiring decisions based on predictions of an employee’s productivity, the allocation of program services prioritized on predictions of who might benefit the most, and pre-trial bail decisions informed by predictions about recidivism.

Dr Melvyn Weeks, University of Cambridge
Dr Melvyn Weeks is a senior lecturer and fellow of Clare College, Cambridge University. Dr Weeks is an assistant editor of the Journal of Applied Econometrics, as well as an associate at Cambridge Econometrics. His work has been published in The Economic Journal, Journal of the American Statistical Association, Journal of Applied Econometrics, European Economic Review, Computational & Economics.
- (1) The Economist, November 21st, 2019.
- (2) NYT, August 12, 2012 - http://www.nytimes.com/2012/08/12/business/how-big-data-became-so-big-unboxed.html
- (3) See https://deepai.org/machine-learning-glossary-and-terms/curse-of-dimensionality.
- (4) See https://www.compasslexecon.com/the-analysis/using-natural-language-processing-in-competition-cases/03-22-2022/
- (5) See Bauer et al (2017).
Related Posts
-
More
-
 More
MoreIs the World Heading for a Soft Landing in 2026?
-
 More
MoreA Generation at Risk: The Realities of Youth Unemployment in Europe and the UK
-
 More
MoreRebuilding Economies After Natural Disasters: What Does The Data Say?
-
 More
MoreAI’s Hidden Cost: The Unanswered Question of Energy Consumption
-
 Cambridge 2025More
Cambridge 2025MoreCausal Machine Learning: Principled Approaches for Econometric Analysis






