
Eksploruj, wizualizuj, modeluj. Lepszy wgląd zaczyna się od Stata
Szybko. Dokładnie. Łatwo w użyciu. Stata to kompletny, zintegrowany pakiet oprogramowania, który zapewnia wszystkie potrzeby związane z nauką o danych — manipulację danymi, wizualizację, statystyki i automatyczne raportowanie.
Kup lub uaktualnij Stata
Zarządzanie danymi
Statystyki
Grafika
Dlaczego Stata?
Szybko. Dokładnie. Łatwo w użyciu. Stata to kompletny, zintegrowany pakiet oprogramowania, który zapewnia wszystkie potrzeby związane z nauką o danych — manipulację danymi, wizualizację, statystyki i automatyczne raportowanie.
|
|
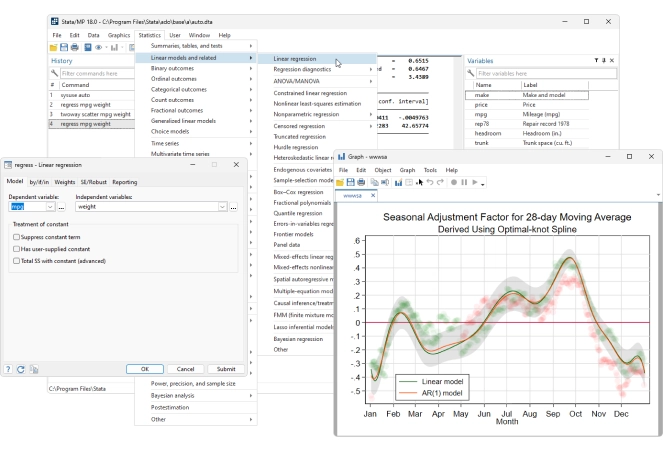
Zapanuj nad swoimi danymi
Funkcje zarządzania danymi Stata dają Ci pełną kontrolę.
|
|
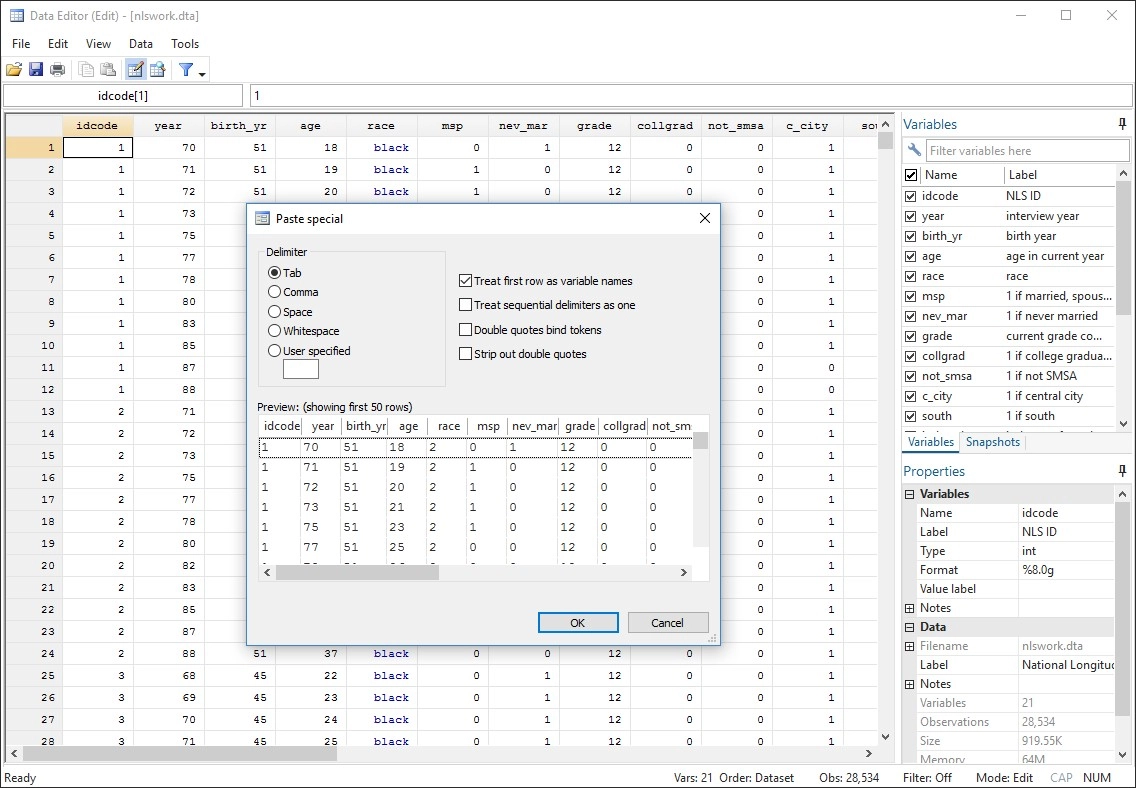
Grafika jakości publikacji
Stata ułatwia generowanie wykresów o wyjątkowej stylistyce i jakości publikacji.
Możesz wskazać i kliknąć, aby utworzyć niestandardowy wykres. Możesz też napisać skrypty, aby wygenerować setki lub tysiące wykresów w sposób powtarzalny.
Eksportuj wykresy do formatu EPS lub TIFF w celu publikacji, do formatu PNG lub SVG w celu umieszczenia w Internecie albo do formatu PDF w celu przeglądania.
Dzięki zintegrowanemu Edytorowi wykresów możesz klikać, aby zmieniać dowolne elementy wykresu lub dodawać tytuły, notatki, linie, strzałki i tekst.
Automatyczne raportowanie
Wszystkie narzędzia potrzebne do automatyzacji raportowania wyników.
- Dokument Dynamic Markdown
- Utwórz dokumenty Word
- Utwórz dokumenty PDF
- Utwórz pliki Excel
- Tabele dostosowywane
- Schematy graficzne
- Słowo, HTML, PDF, SVG, PNG
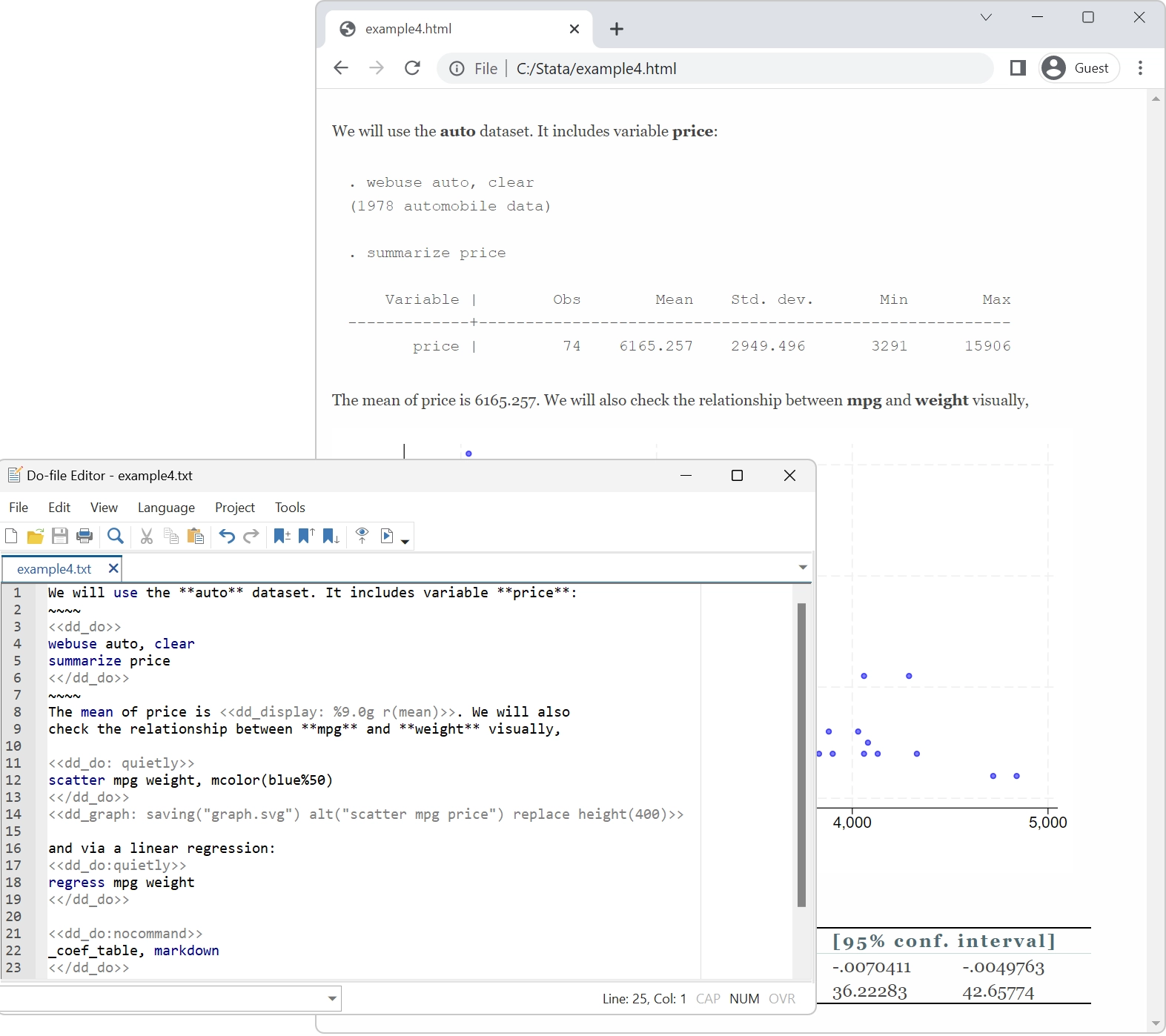
Badania naprawdę powtarzalne
Wiele osób mówi o powtarzalnych badaniach. Stata poświęca się temu od ponad 30 lat.
Ciągle dodajemy nowe funkcje; nawet fundamentalnie zmieniliśmy elementy języka. Nieważne. Stata jest jedynym pakietem statystycznym ze zintegrowanym wersjonowaniem. Jeśli napisałeś skrypt do wykonania analizy w 1985 r., ten sam skrypt nadal będzie działał i nadal będzie generował te same wyniki dzisiaj. Każdy zestaw danych, który utworzyłeś w 1985 r., możesz odczytać dzisiaj. I to samo będzie prawdą w 2050 r. Stata będzie w stanie uruchomić wszystko, co robisz dzisiaj.
Powtarzalność wyników jest dla nas kwestią priorytetową.
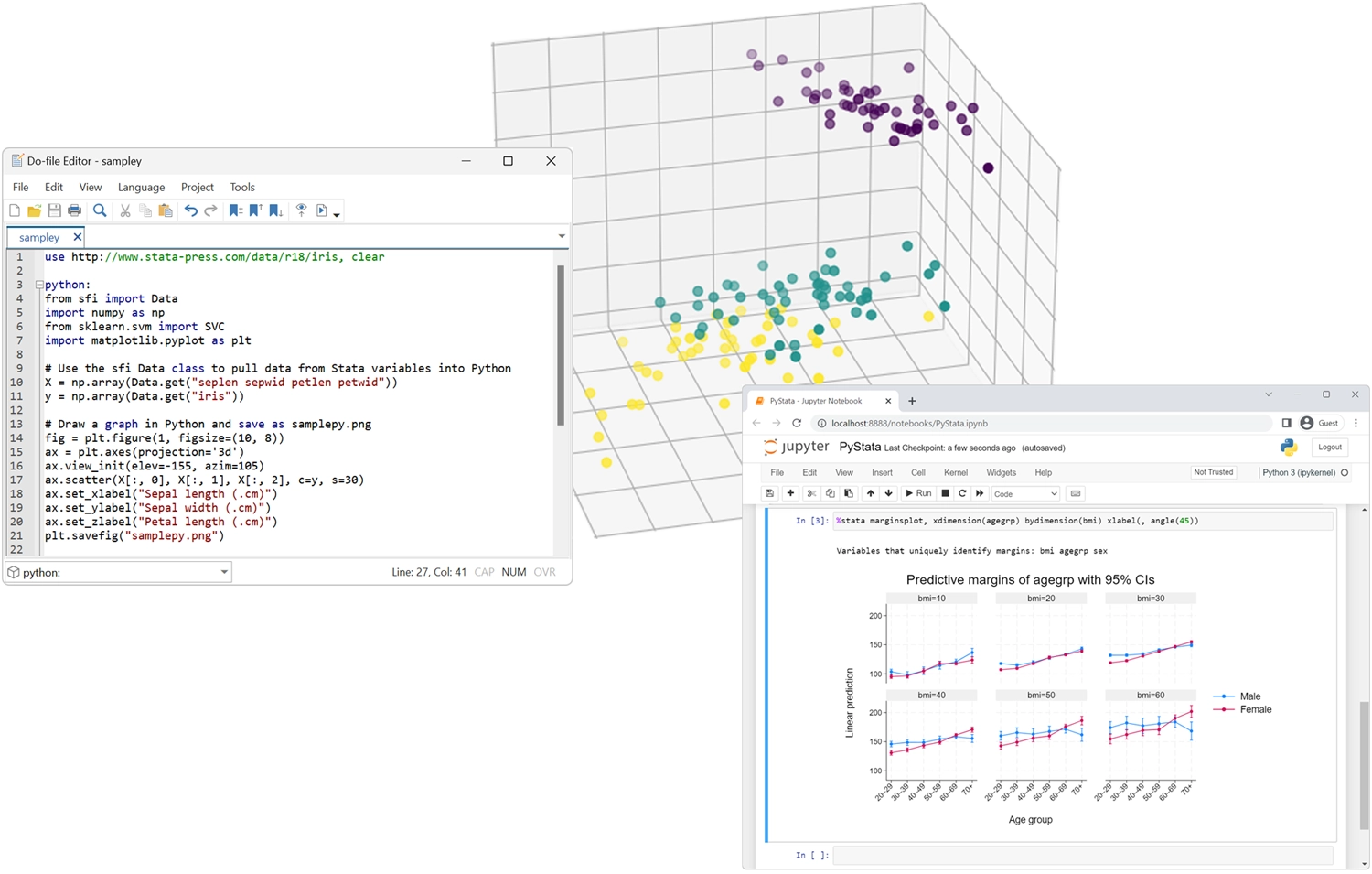
PyStata — integracja z Pythonem
Wywołuj Pythona interaktywnie lub osadź go w kodzie Stata.
Wywołanie Stata z poziomu Pythona i wywołanie kodu Stata ze środowisk IPython.
Użyj Stata w Jupyter Notebook.
Bezproblemowe przesyłanie danych i wyników między Statą i Pythonem.
Używaj analiz Stata z poziomu Pythona.
Użyj dowolnego pakietu Python w Stata
- Matplotlib i seaborn do wizualizacji
- Beautiful Soup i Scrapy do scrapowania sieci
- NumPy i pandas do analizy numerycznej
- TensorFlow i scikit-learn do uczenia maszynowego
- I wiele więcej
Prawdziwa dokumentacja
Kiedy przychodzi czas na przeprowadzenie analiz lub zrozumienie stosowanych przez Ciebie metod, Stata nie pozostawia Cię samego sobie ani nie wymaga zamawiania książek, abyś zgłębił każdy szczegół.
Każda z naszych funkcji zarządzania danymi jest w pełni wyjaśniona, udokumentowana i pokazana w praktyce na prawdziwych przykładach. Każdy estymator jest w pełni udokumentowany i zawiera kilka przykładów na prawdziwych danych, z prawdziwymi dyskusjami na temat tego, jak interpretować wyniki. Przykłady dostarczają danych, dzięki czemu możesz pracować w Stata, a nawet rozszerzać analizy. Dajemy Ci Szybki start dla każdej funkcji, pokazując niektóre z najczęstszych zastosowań. Chcesz jeszcze więcej szczegółów? Nasze sekcje Metody i wzory zawierają szczegóły tego, co jest obliczane, a nasze Odniesienia kierują Cię do jeszcze większej ilości informacji.
Stata to duży pakiet, więc ma mnóstwo dokumentacji – ponad 18 000 stron w 35 podręcznikach. Ale nie martw się, wpisz help my topic, a Stata przeszuka swoje słowa kluczowe, indeksy, a nawet pakiety dodane przez społeczność, aby dostarczyć Ci wszystkiego, co musisz wiedzieć o swoim temacie. Wszystko jest dostępne bezpośrednio w Stata.
Zaufany
Nie tylko programujemy metody statystyczne, ale także je weryfikujemy.
Wyniki, które widzisz z estymatora Stata, opierają się na porównaniach z innymi estymatorami, symulacjach spójności i pokrycia metodą Monte Carlo oraz obszernych testach przeprowadzanych przez naszych statystyków. Każdy Stata, który wysyłamy, przeszedł zestaw certyfikacji obejmujący 4,1 miliona wierszy kodu testowego, który generuje 5,8 miliona wierszy wyników. Certyfikujemy każdą liczbę i fragment tekstu z tych 5,8 miliona wierszy wyników.
Niezawodny
Od ponad 35 lat StataCorp jest lojalny wobec swoich użytkowników, rozszerzając oprogramowanie Stata o nowe metody statystyczne i najnowsze rozwiązania w zakresie raportowania, wizualizacji danych, manipulacji danymi i interfejsu użytkownika. Dzięki naszej długiej historii wydań jesteśmy zobowiązani do ciągłego dostarczania stabilnego i niezawodnego oprogramowania naszej zróżnicowanej społeczności badaczy i praktyków.
![]()
Ciągle aktualizowane
Korzystanie z najnowszej wersji oprogramowania Stata jest teraz łatwiejsze niż kiedykolwiek.
StataCorp nieustannie rozwija nowe funkcje, aby udoskonalić oprogramowanie Stata, od najnowszych metod statystycznych po najlepsze w zakresie raportowania, wizualizacji danych i interfejsu użytkownika. Dzięki StataNow™ nowe funkcje są udostępniane w trakcie bieżącej wersji aż do następnej głównej wersji. Funkcje te są priorytetowo traktowane w cyklu rozwoju, aby były dostępne, gdy tylko będą gotowe, dzięki czemu użytkownicy będą mogli z nich korzystać od razu.
![]()
Łatwy w użyciu
Korzystanie z najnowszej wersji oprogramowania Stata jest teraz łatwiejsze niż kiedykolwiek.
Do wszystkich funkcji Stata można uzyskać dostęp za pomocą menu, okien dialogowych, paneli sterowania, Edytora danych, Menedżera zmiennych, Edytora wykresów, a nawet Kreatora diagramów SEM. Możesz wskazywać i klikać, aby przejść przez dowolną analizę.
Jeśli nie chcesz pisać poleceń i skryptów, nie musisz tego robić.
Nawet gdy wskazujesz i klikasz, możesz zapisać wszystkie swoje wyniki i później uwzględnić je w raportach. Możesz nawet zapisać polecenia utworzone przez Twoje działania i odtworzyć całą analizę później.
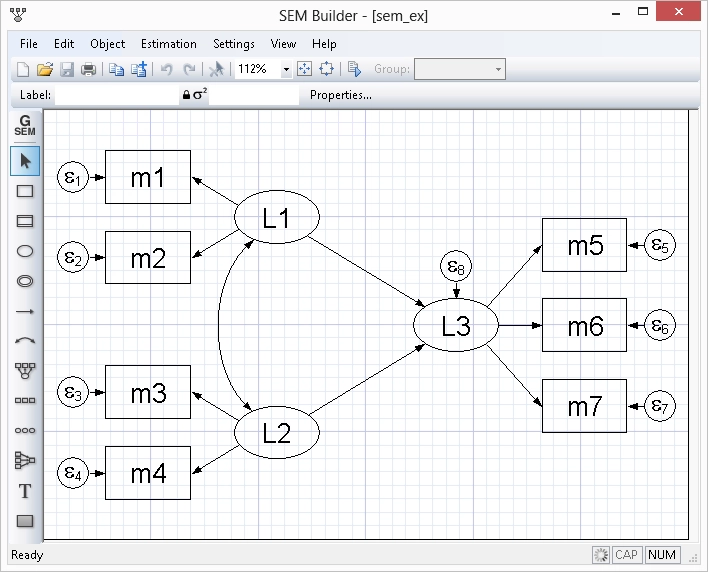
Łatwy w uprawie
Polecenia Stata do wykonywania zadań są intuicyjne i łatwe do nauczenia. Co więcej, wszystko, czego nauczysz się o wykonywaniu zadania, można zastosować do innych zadań. Na przykład, po prostu dodaj if gender=="female" do dowolnego polecenia, aby ograniczyć analizę do kobiet w próbie. Po prostu dodaj vce(robust) do dowolnego estymatora, aby uzyskać błędy standardowe i testy hipotez, które są odporne na wiele typowych założeń.
Spójność sięga jeszcze głębiej. To, czego dowiadujesz się o poleceniach zarządzania danymi, często odnosi się do poleceń estymacji i odwrotnie. Istnieje również pełen zestaw poleceń postestymacji do przeprowadzania testów hipotez, tworzenia kombinacji liniowych i nieliniowych, dokonywania przewidywań, tworzenia kontrastów, a nawet przeprowadzania analizy marginalnej z wykresami interakcji. Te polecenia działają w ten sam sposób po praktycznie każdym estymatorze.
Sekwencjonowanie poleceń do odczytu i czyszczenia danych, a następnie do wykonywania testów statystycznych i szacowania, a na końcu do raportowania wyników leży u podstaw powtarzalnych badań. Stata udostępnia ten proces wszystkim badaczom.
![]()
Łatwe do zautomatyzowania
Każdy ma zadania, które wykonuje cały czas — tworzy konkretny rodzaj zmiennej, produkuje konkretną tabelę, wykonuje sekwencję kroków statystycznych, oblicza RMSE itd. Możliwości są nieograniczone. Stata ma tysiące wbudowanych procedur, ale możesz mieć zadania, które są stosunkowo wyjątkowe lub które chcesz wykonać w określony sposób.
Jeśli napisałeś skrypt wykonujący zadanie na danym zestawie danych, możesz łatwo przekształcić ten skrypt w coś, co będzie można zastosować do wszystkich zestawów danych, dowolnego zestawu zmiennych i dowolnego zestawu obserwacji.
![]()
Łatwy do rozszerzenia
Niektóre z rzeczy, które automatyzujesz, mogą być tak przydatne, że chcesz się nimi podzielić ze współpracownikami, a nawet udostępnić je wszystkim użytkownikom Stata. To również jest proste. Za pomocą odrobiny kodu możesz zmienić skrypt automatyzacji w polecenie Stata. Polecenie, które obsługuje standardowe funkcje obsługiwane przez oficjalne polecenia Stata. Polecenie, którego można używać w taki sam sposób, w jaki używa się oficjalnych poleceń.
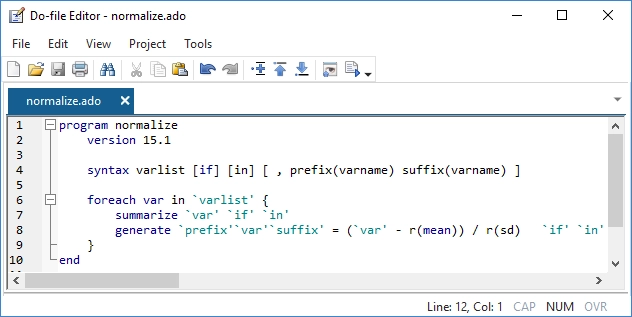
Zaawansowane programowanie
Stata zawiera również zaawansowany język programowania — Mata.
Mata zawiera struktury, wskaźniki i klasy, których można oczekiwać w języku programowania, a ponadto zapewnia bezpośrednie wsparcie dla programowania macierzowego.
Chociaż nie musisz programować, aby używać Stata, pocieszające jest wiedzieć, że szybki i kompletny język programowania jest integralną częścią Stata. Mata jest zarówno interaktywnym środowiskiem do manipulowania macierzami, jak i pełnym środowiskiem programistycznym, które może generować skompilowany i zoptymalizowany kod. Zawiera specjalne funkcje do przetwarzania danych panelowych, wykonuje operacje na rzeczywistych lub złożonych macierzach, zapewnia pełne wsparcie dla programowania obiektowego i jest w pełni zintegrowany z każdym aspektem Stata. Stata ma również kompleksową integrację z Pythonem, co pozwala na wykorzystanie całej mocy Pythona bezpośrednio z kodu Stata.
Stata ma również PyStata, który zapewnia kompleksową integrację z Pythonem, umożliwiając wykorzystanie całego potencjału Pythona bezpośrednio z kodu Stata i wykorzystanie całego potencjału Stata z kodu Pythona.
Stata pozwala nawet na włączenie wtyczek C, C++ i Java do programów Stata za pośrednictwem natywnego API dla każdego języka. Możesz nawet osadzić kod Java bezpośrednio w kodzie Stata!
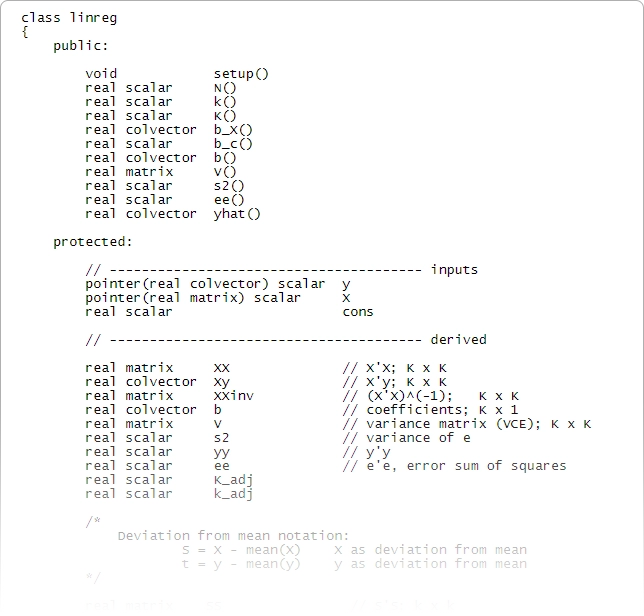

Funkcje dodane przez społeczność
Stata jest tak programowalna, że programiści i użytkownicy codziennie dodają nowe funkcje, aby sprostać rosnącym wymaganiom dzisiejszych badaczy.
Dzięki możliwościom internetowym Stata nowe funkcje i oficjalne aktualizacje można zainstalować przez Internet za pomocą jednego kliknięcia.
Wsparcie techniczne na światowym poziomie
Wszyscy zarejestrowani użytkownicy aktualnej wersji Stata (Stata 18) kwalifikują się do bezpłatnego wsparcia technicznego. Jeśli nie zarejestrowałeś swojej kopii Stata, wypełnij formularz rejestracyjny online.
Mamy oddany zespół ekspertów programistów Stata i statystyków, którzy odpowiedzą na Twoje pytania techniczne. Od skomplikowanych rozwiązań zarządzania danymi po uzyskanie odpowiedniego wyglądu wykresu i od wyjaśnienia solidnego błędu standardowego po określenie modelu wielopoziomowego, mamy odpowiedzi.
![]()
Kompatybilny z wieloma platformami
Stata będzie działać na komputerach z systemami Windows, Mac i Linux/Unix; jednak nasze licencje nie są specyficzne dla platformy. Oznacza to, że jeśli masz laptopa Mac i komputer stacjonarny z systemem Windows, nie potrzebujesz dwóch oddzielnych licencji, aby uruchomić Stata. Możesz zainstalować licencję Stata na dowolnej z obsługiwanych platform. Zestawy danych Stata, programy i inne dane mogą być udostępniane na różnych platformach bez tłumaczenia. Możesz również szybko i łatwo importować zestawy danych z innych pakietów statystycznych, arkuszy kalkulacyjnych i baz danych.
Szeroko stosowany
Z narzędzia Stata korzystają naukowcy od ponad 35 lat. Oferuje ono wszystko, czego potrzeba do nauki o danych, czyli manipulację danymi, wizualizację, statystykę i automatyczne raportowanie.
Wybierz swoją dyscyplinę i sprawdź, jak Stata może Ci pomóc.
{{typ widżetu-no-translate-custom="Magento\Cms\Block\Widget\Block" szablon="widget/static_block/default.phtml" identyfikator_bloku="stata-usage"}}
Przedstawiamy StataNow™
Nowe funkcje udostępniane z prędkością Stata. Dzięki StataNow zawsze będziesz mieć najnowsze funkcje.
StataNow to wersja oprogramowania Stata udostępniana w trybie ciągłym, oferująca nowe funkcje natychmiast po ich opracowaniu i gwarantująca użytkownikom stały dostęp do najnowszej wersji oprogramowania Stata.
Prosto z rozwoju do Ciebie. Dzięki StataNow zawsze masz dostęp do najnowszych funkcji.
Wymagania systemowe
| OS | Komputery Mac z systemem Windows 10 i procesorem Apple Silicon oraz macOS 10.13 lub nowszym dla komputerów Mac z procesorami Intel |
|---|---|
| Processor | Apple Silicon, Intel lub AMD Processor (Core i3 lub plus) |
| Memory | Stata/MP > 4GB, Stata/SE > 2GB, and Stata/BE 1GB |
| Hard Drive | 4 GB |
| Graphics | ATI Radeon 8500 or Nvidia GeForce 4 or higher video card |
Stata w Twoich badaniach
Oprogramowanie Stata, z którego korzystają setki tysięcy badaczy od ponad 35 lat, zapewnia wszystko, czego potrzeba do nauki o danych, czyli manipulację danymi, wizualizację, statystykę i powtarzalne raportowanie.
Wybierz swoją dyscyplinę i sprawdź, jak Stata może Ci pomóc.
Oprogramowanie Stata, z którego korzystają setki tysięcy badaczy od ponad 35 lat, zapewnia wszystko, czego potrzeba do nauki o danych, czyli manipulację danymi, wizualizację, statystykę i powtarzalne raportowanie.
Wybierz swoją dyscyplinę i sprawdź, jak Stata może Ci pomóc.
Blog
-
Więcej
-
 Więcej
WięcejGreenflation or Transformation? Unpacking Energy Prices in the Transition Era
-
 Więcej
WięcejIs the World Heading for a Soft Landing in 2026?
-
 Więcej
WięcejA Generation at Risk: The Realities of Youth Unemployment in Europe and the UK
-
 Więcej
WięcejRebuilding Economies After Natural Disasters: What Does The Data Say?
-
 Więcej
WięcejAI’s Hidden Cost: The Unanswered Question of Energy Consumption








